A recent press release gives some information on how censorship is performed in the Chinese version of Skype; the results are discussed in more detail in a paper by Jeffrey Knockels, Jed Crandall and myself. Currently, a significant portion of Internet censorship is keyword based: any content that contains a keyword that is on some blacklist is censored. Countries that perform keyword censorship generally try to hide these blacklists, probably both for political reasons and to make it difficult to evade censorship by using neologisms: new words that have the same meaning but are not on the blacklist.
In some peer-to-peer applications, this censorship is done on the client side, so there is a subroutine in, e.g. Skype chat, that checks if an outgoing message contains a keyword on the blacklist. If you are the censor and you don’t care about revealing the blacklist, then there are techniques for doing this in an efficient manner (hint: FSA’s). However, it’s an interesting (but evil) theoretical problem to think about how to efficiently do keyword censorship if you are also trying to also hide the blacklist. In particular, if you want to hide it from someone who may be running your executable in a debugger. Hint: the Chinese Skype program did it incorrectly and that’s why we were able to decrypt their blacklist!
Filed under: Uncategorized | Tags: distributed computing, papers, reliability, theory
In today’s post, I want to focus on some of the highlights of the lower bound that I mentioned last time on the “Networks of Noisy Gates“ problem. Recall that, in this problem, you are given a function 



The result I want to talk about today is the lower bound by Pippenger, Stamoulis and Tsitsiklis which shows that there are some functions that can be computed with 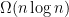
The first part of their lower bound is a result that shows a new model of failure where wires can also fail can be made equivalent to the old model of failure where only gates can fail. In particular, in the new model, each wire fails with some probability 
Lemma 3.1 of the paper “Lower Bound for the Redundancy of Self-correcting Arrangements of Unreliable Functional Elements” by Dobrushin and Ortyukov shows the following. Let 
![{\delta \in [0, \epsilon/\Delta]}](https://s0.wp.com/latex.php?latex=%7B%5Cdelta+%5Cin+%5B0%2C+%5Cepsilon%2F%5CDelta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Now we assume we have 


For the 


Next, note that the probability that the noisy circuit fails is just 

Proof: Let 








But by linearity of expectation, 




The remainder of the proof for the lower bound is just algebra. We’ll make use of the inequality between arithmetic and geometric means, which states that for any set of 
![{(1/n) \sum_{i=1}^{n} x_{i} \geq \sqrt[n] {\prod_{i=1}^{n} x_{i}}}](https://s0.wp.com/latex.php?latex=%7B%281%2Fn%29+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+x_%7Bi%7D+%5Cgeq+%5Csqrt%5Bn%5D+%7B%5Cprod_%7Bi%3D1%7D%5E%7Bn%7D+x_%7Bi%7D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Lemma 2
is

Proof: Let 



Now using the inequality between arithmetic and geometric means, we have that

Again using the inequality between arithmetic and geometric means (now on the term that is being subtracted) and the fact that 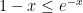

Isolating the 

Since
Finally, we note that since each gate is assumed to have constant fan in, if the number of wires is
The current issue of Computer Science Review is devoted to celebrating the research contributions of Papadimitriou [1]. The issue contains a nice mix of accolades and ideas. On the accolades side, I was impressed by the degree to which Papadimitriou has helped create a vibrant theory community in his home country of Greece, which has produced more than its fair share of notable theory researchers.
On the idea side, there are two survey papers of work connected to Papadimitriou that I particularly liked, one by Koutsoupias on the k-server problem and one by Kleinberg and Raghavan on internet structure, network routing and web information. One of the very first dissertations I ever read was Koutsoupias’ dissertation (done under Papa.), which showed that the work function algorithm for the k-server problem had a competitive ratio of 2k-1, where the previous best known ratio was exponential in k. This dissertation helped me fall in love with CS theory: beautiful math and ideas, a crisp problem statement, a clear understanding of when progress is made on a problem. Plus, the entire dissertation is only 41 pages – that’s perhaps the best way to appreciate what a major result it was!
Bonus Papadimitriou link: Check out the following Papa. talk on why “CS is the new math”.
[1] Tip of the hat to journal editor-in-chief and friend Josep Diaz who air-mailed me the current issue of the journal. A very enjoyable part of my sabbatical last year was spent in Barcelona at UPC working with Josep.
Piere Fraigniaud and George Giakkoupis from the University of Paris at Diderot have a really nice paper in this upcoming Principles of Distributed Computing (PODC). Their paper titled “The Effect of Power-Law Degrees on the Navigability of Small Worlds” builds on the classic paper by Jon Kleinberg on navigating small world networks.
Jon Kleinberg’s classic paper concerns navigation in a grid network where each node, in addition to its local edges, has one additional long range edge. What Kleinberg showed is that provided that, for each node, this long range link covers a distance d with probability proportional to d^2, then a greedy routing algorithm will ensure that any node can reach any other node in the network within no more than about log^2 n hops where n is the number of nodes in the network[1]. Moreover, the exponent in this probability is pretty important, even a slight deviation from an exponent of 2 results in networks that can not be efficiently navigated by greedy algorithms. In this way, Kleinberg was thus one of the first people to describe a type of network that might mimic the social network that allowed quick routing in Stanley Milgram’s famous six degrees of separation experiments.
So what about this new paper by Piere and George? Well for many years the exponent of 2 in log^2 has bothered people. Piere and George show that it is possible to get rid of it with power laws. In particular, they show that if instead of each node having exactly 1 long distance link, the number of long distance links per node follows a certain powerlaw distribution, then greedy routing works in about log n hops. A powerlaw distribution means that the number of nodes with a number of long distance links x is proportional to x^k for some fixed constant k. This is a so called heavy tail distribution which occurs in many natural complex systems. Surprisingly, Piere and George show that the type of powerlaw distribution for which greedy routing works is when k is in the range between 2 and 3, which is very similar to the exponent one observes for degree distributions in many naturally occuring social networks.
As far as I know this is one of the first papers that suggests a nice functional property of powerlaw distributions. In particular, it shows that powerlaw distributions are more powerful than other distributions in achieving a specific mathematical goal. Are there other algorithmic or mathematical problems that powerlaw distributions are “good” for. It looks like a very nice paper.
[1] I’m using the term about to meet O(log^2 n) or roughly a function that grows like C log^2 n for some fixed constant C.
